ZDDを真面目に解説する話【Daily Akari ソルバー実装編 1/3】
はじめに
前回の記事↓ で、Daily Akari というパズルの ZDD による解法をサラッと紹介しました。
しかし、どうにも 「ZDD とはなんぞや?」「よくわからんが難しそう」といった風に感じている人がなんとなく多そうな気がしており、これは由々しき事態だなと。
ZDD はすんごくシンプルなアイデアで色々な問題を解けてしまう激面白データ構造なので、何としてでも布教したいと思いました。
なので、アルゴリズム学徒だけでなくプログラミングにそこまで明るくない非応用数学系の人々にも届くように一から丁寧に解説していきます。ゴールがあった方がいいと思うので、Daily Akari ソルバーの作成を目標にしてしまいましょう。
目指せ、一家に一台 ZDD!
なお、全体の実装例は ↓ に置いてあります。
(本記事シリーズでは Java の方を実装していきます。)
この記事でやること
この記事でやらないこと
- ZDD の演算の話(第2回でガッツリやる予定。ZDD の激面白ポイントはここ。)
- Daily Akari の話(第3回で入る予定。気長にやりましょう。)
1. ZDD の概要
1.1. ZDD とは
Zero-supressed Binary Dicision Diagram の略です。日本語では「ゼロサプレス(抑制?)型二分決定グラフ」になります。あまり日本語で呼ばれているところは見ないですが、提案されたのは日本の教授、湊真一先生です[1]。2025年現在は京大で教鞭をとられています。
与えられた集合 に対して、ZDD は部分集合族
を表現します。以下では
を 台集合、
を アイテム、各部分集合
を 組合せ集合 と呼びます。
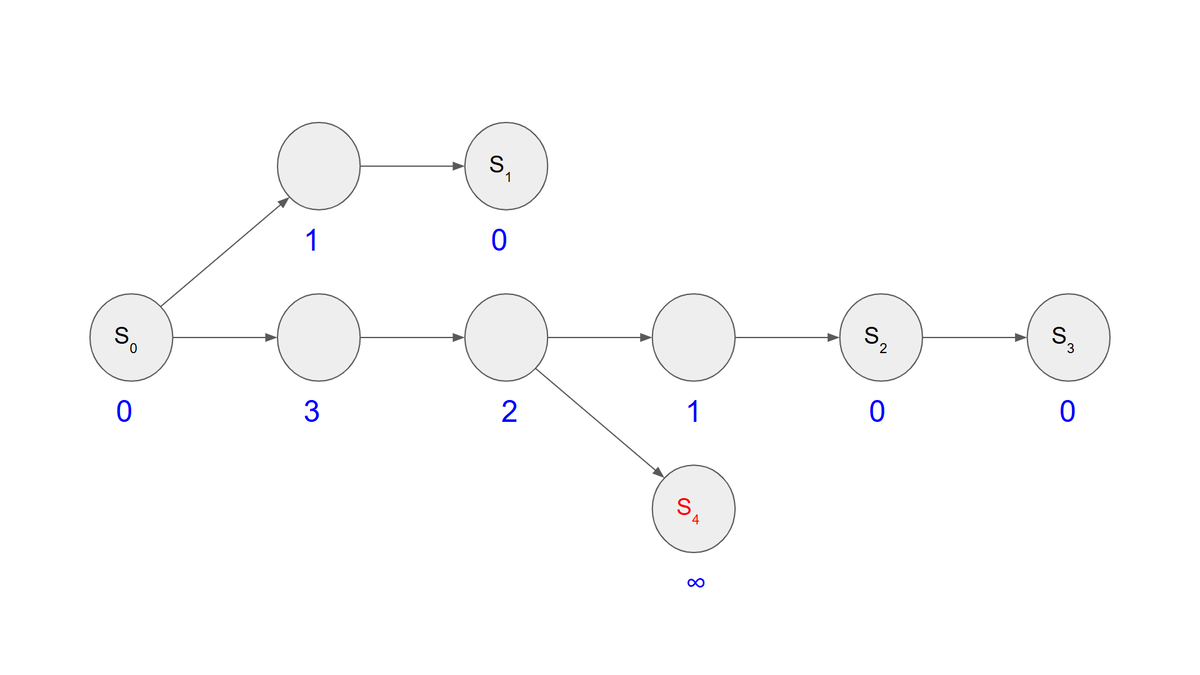
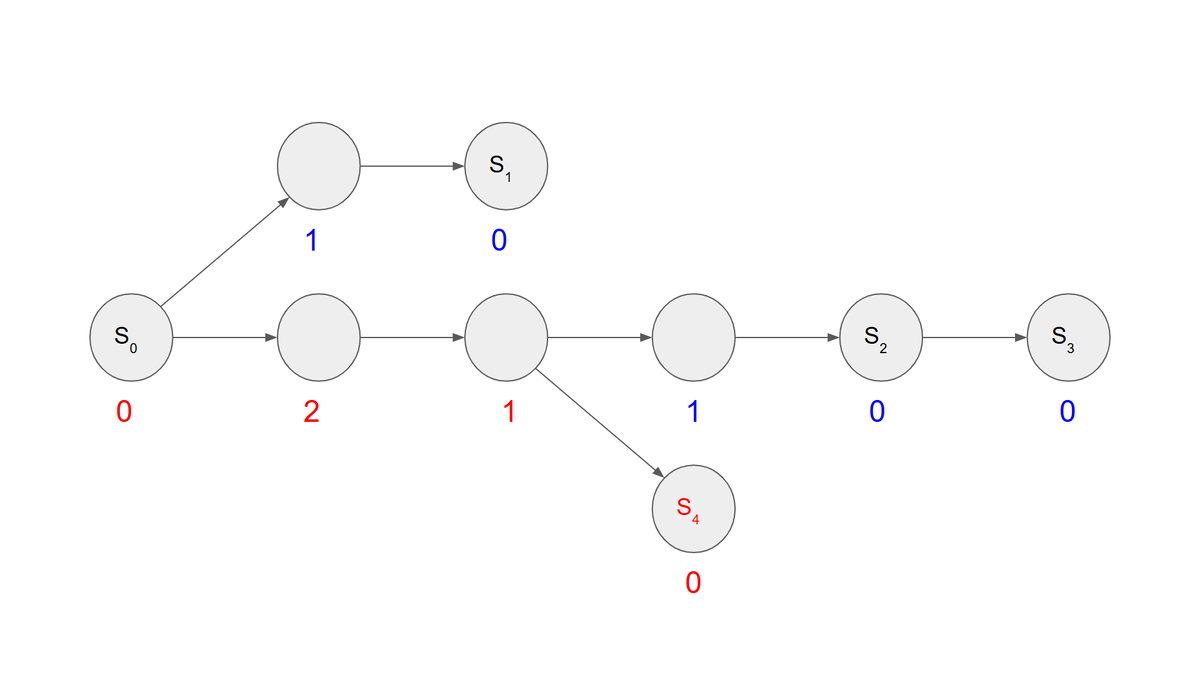
例えば、 に対し
を表す ZDD は【図 1.1-1】になります。

【図 1.1-1】において、赤い辺を 0-枝、青い辺を 1-枝と呼びます。また、一番上の のラベルがついた節点を 根、一番下の
のラベルがついた節点を 0-終端節点、
のラベルがついた節点を 1-終端節点 と呼びます。
終端節点を除く各節点からは、それぞれ0-枝と1-枝が1つずつ出ています。これが、「二分決定グラフ」と呼ばれる所以です。
ZDD において、根から1-終端節点までのパスが各組合せ集合に対応します。
すなわち、各パスについて節点から出る際に
- 1-枝を通るなら、その節点のアイテムを組合せ集合に追加する。
- 0-枝を通るなら、追加しない。
とすることで組合せ集合と対応付けます。(【図 1.1-2】)

特に、この対応付けになぞらえると、0-終端節点のみからなる ZDD は部分集合族 を、 1-終端節点のみからなる ZDD は部分集合族
をそれぞれ表していることに注意してください。
以上が、ZDD の"読み方"になります。
この説明だけ聞くと「どこからそのグラフは降ってきたんですか?」という疑問が出ると思うので、次はその解説をします。
1.2. ZDD の基礎的な構成方法
前節に引き続き、台集合 に対し部分集合族
を表す ZDD を例にしましょう。
まず、【図 1.2-1】に示す完全二分決定木を考えます。

この木において、根から各終端節点までのパスは の全ての部分集合と対応付けられます。特に、終端節点の
と
を切り替えることで任意の部分集合族(アイテム数が
なら、
通り)を表現できることに注意してください。
さて、このままだと節点数が となり、
が大きいと困ってしまいます。実用上は表現したい部分集合族がべき集合に対して十分疎であることが多いので、もっと効率的に表現したいところ。
そこで、次の2つの圧縮規則(【図 1.2-2】)を導入します。
- 削除規則:
1-枝の先が0-終端節点であるような節点を省略する。 - 共有規則:
等価な節点(ラベル、0-枝の行先、1-枝の行先が同一である節点)を纏める。特に、終端節点も等価な節点とみなす。

この2つの圧縮規則を、【図 1.2-1】で示した完全二分決定木に対し(任意の手順で)繰り返し適用することで、最終的に【図 1.1-1】に示す ZDD が得られます*1。また、この圧縮規則が適用できない状態のことを既約であると言います*2。
というわけで、ZDD の構成法が得られました。
しかし、この構成法には大きな問題があります。
というのも、最初に完全二分決定木を作ってしまうと、その時点で計算量が爆発してしまいます。
目標としている Daily Akari ソルバーにおいては、台集合をマス全体として、解であるような灯りの置き方(=マスの部分集合)全体から成る ZDD を構成します。グリッドサイズは最大 なので*3、完全二分決定木の節点数は
になってしまいます。これは宇宙の原子の数より多いらしいので[2]、この構成法は物理的に不可能です。
というわけで、本節で解説した完全二分決定木を経由する構成法は、現実的ではありません。ただし、2種類の圧縮規則とアイテムの添字順(=完全二分決定木上でアイテムをどの順に置くか)によって ZDD の形状が定まっているということは、知識として知ってくおくとよいでしょう。
次項では、「じゃあ結局 ZDD ってどう作るの?」という疑問に答えていきます。
1.3. ZDD の効率的な構成方法
1.3.1. 部分集合族の分解
ZDD の各接点は、それ自体を根とする ZDD と捉えられ、対応する部分集合族が存在します。そこで、根の0-枝の先と1-枝の先がそれぞれどのような部分集合族を表しているかを考えます。
以下、台集合を とします。
また、便利な記号として、部分集合族 とアイテム
に対する二項演算子
を次のように定義します。
\begin{equation} \mathcal{P} \triangleleft e_i := \{P \cup \{e_i\} \mid P \in \mathcal{P}\} \tag{1}\end{equation}
すると、任意の非空な組合せ集合を少なくとも1つもつ部分集合族 について、
\begin{align} e_i & := \min(\bigcup_{P \in \mathcal{P}} P) \\ \mathcal{P}_0 & := \{P \mid e_i \notin P \in \mathcal{P}\} \tag{2}\\ \mathcal{P}_1 & := \{P \setminus \{e_i\} \mid e_i \in P \in \mathcal{P} \} \end{align}
(アイテムの大小は添字で比較するものとします。)とおいたとき、次式が成り立ちます。
\begin{equation} \mathcal{P} = \mathcal{P}_0 \cup (\mathcal{P}_1 \triangleleft e_i) \tag{3}\end{equation}
この 式(3) は、【図 1.3.1-1】に示す ZDD の抽象図をそのまま表現しています。

ふわふわとお絵描きしていたものが、かっちりと扱えそうになってきましたね。
1.3.2. 圧縮規則の再帰的な適用
さて、勘のいい読者は気づかれているかもしれませんが、式(3) は ZDD の再帰的な構成方法を示唆しています。
すなわち、 と
に対応した ZDD が得られていると仮定すると、そこに
をラベルに持つ節点を追加し、枝を エイヤッ!! とそれぞれの根に突き刺すことで、
の ZDD が完成しそうです。
この枝を エイヤッ!! する操作に圧縮規則を適用したものが、次の手続き になります。
-
なら、
の根を返す。
- そうでないなら、以下の節点を作成して返す。ただし、等価な節点を既に作成済みならそれを返す。
- ラベル:
- 0-枝の先:
- 1-枝の先:
の根
- ラベル:
この手続きを用いることで、与えられた部分集合族 に対し ZDD を構築しその根を返す手続き
は、下記のように再帰的に記述できます。
なら、0-終端節点を返す。
なら、1-終端節点を返す。
- 上記以外なら、式(2) により
を得て、
を返す。
というわけで、ZDD の良い構成方法が得られました。
しかし、この という手続きは、部分集合族
を表現する手段が存在する前提で記述されており、結局それをどう実装するのか?という点で言えばあまり意味を成しません*4。大事なのは、このように再帰的に記述できることを理解しておくことです。
(ちなみに、最初からこの という手続きで ZDD を定義してしまっても問題ありません。数学的にはその方が簡潔かもしれませんね。)
「え、じゃあ結局 ZDD ってどうやって使うの???」
とツッコミが入るかもしれませんが、解説する分量の都合上、次回までお待ちください。実際のところそのあたりが ZDD で一番面白い話で「おわりに」の章でも軽く触れますが、本記事ではとにかく ZDD のベースとなる部分の実装を目指します。
1.3.3. ハッシュ関数
1.3.2項 にて という手続きを紹介しましたが、これを実装するうえでは等価節点をどのように保存・検索するのかという点にも着目しなくてはなりません。いわゆるデータ構造ってやつです。(ZDD も部分集合族を表現するためのデータ構造と言えます。)
計算機で扱える基本的なデータ構造として、配列があります。これは、複数のデータを1列に並べたもので、任意の非負整数 に対し
番目*5のデータの読み書きを高速に処理できます。なお、計算機のメモリにも限りがあるため、配列の長さとして有限な非負整数
を決めておく必要があります。
そして、配列を流用するデータ構造として、ハッシュテーブルというものがあります。
ハッシュテーブルは、保存したいデータに対し予め用意した"いい感じの関数"を使って 以上
未満の非負整数
に変換し、配列の
番目に保存すると取り決めたものです。この"いい感じの関数"をハッシュ関数と呼びます。また、ハッシュ関数で得られた整数値のことをハッシュ値と呼びます。
(用意した関数が単射でない場合、異なるデータに対して同じ番地が充てられてしまう場合があり、これを衝突と呼びます。衝突した場合にどう保存するかは別途取り決めておく必要があるのと、そもそも衝突があまり起きないように関数を定義することが重要です。)
ハッシュテーブルに ZDD の節点を保存できれば、検索が高速にできてうれしいです。なので、サクッとハッシュ関数を作ってしまいましょう*6。
ハッシュ関数を作る上での便利な道具として、Xorshift と RollingHash という 2 つの関数を使います。具体的な中身はリンク先の解説が易しいのでそちらを参照ください。
:
正整数値を何かしらの正整数値に飛ばす疑似乱数発生器
blog.visvirial.com:
任意長の正整数列を何かしらの法
の整数値に飛ばすハッシュ関数
maspypy.com
0-終端節点のハッシュ値を 、
1-終端節点のハッシュ値を とします。
終端節点でない節点 について、ラベルのアイテムを
、0-枝の先を
、1-枝の先を
とし、
と
のハッシュ値は既に求まっていると仮定します。
この のハッシュ値を次のように定義します:
\begin{align} \text{hash}(\mathcal{P}) := \text{RollingHash}(& \text{Xorshift}(i+1), \\ & \text{Xorshift}(\text{hash}(\mathcal{P}_0)+1), \tag{4} \\ & \text{Xorshift}(\text{hash}(\mathcal{P}_1)+1)) \end{align}
要するに、アイテムと枝の先にある2節点のハッシュ値から自身のハッシュ値を定めているわけですね。これでハッシュ関数の完成です。
以上で ZDD のベースとなる考え方の解説は終了です。
次章からは実装に入っていきます。
2. 実装
zddForDailyAkari パッケージに、続く3つのクラスを実装します。
なお、3つ目の ZDD_Visualizer はなくてもDailyAkari は解けるので、飛ばしても問題ありません。
2.1. RollingHash クラス
式(4) に基づいたハッシュ関数を実装したクラスです。 RollingHash という名前ですが、中に Xorshift も内蔵しています。
コンストラクタは 法 m を引数に取り、コンストラクタ内で基数 r を乱択しています。これは Rolling Hashについて(survey + 研究) | maspyのHP にて解説された内容を実装したものになります。
2.2. ZDD<T>、ZDD<T>.ZDD_Node クラス
ZDD クラスと、その内部クラスとして節点を表す ZDD_Node クラスを実装しています。これは、台集合や節点のハッシュテーブルを ZDD クラスに管理してもらいたいという思想があるからです。 また、1.3.2項 ので解説した も ZDD クラスのメソッドとします。
T はアイテムのクラスを表します。ZDD<T> のコンストラクタは台集合として ArrayList<T> を引数に取り、ArrayList での順に沿ってアイテムの添字を決定します。
決定した添字は HashMap<T, Integer> idx に保存しています。
ZDD_Node クラスでは hashCode() と eauals() をオーバーライドしています。
注意点として、equals() 内の
this.zero == o.zero && this.one == o.one
としている箇所を
this.zero.equals(o.zero) && this.one.equals(o.one)
としてしまうと、equals() が終端節点まで再帰的に呼び出されてしまい計算量が爆発してしまいます。 で適用される共有規則を踏まえると、「==」での比較(同一のインスタンスかどうかの比較)で十分です。
同様に、終端節点まで hashCode() が再帰的に呼び出されることを回避するため、コンストラクタ内でハッシュ値を予め計算し保存しておくようにしています。
2.3. ZDD_Visualizer<T> クラス
外部ライブラリである jung-2.0.1 を利用するため、導入方法をまず紹介します。
まず、下記リンクからライブラリの圧縮ファイルをダウンロードしてください。
ダウンロードした圧縮ファイルを適当なディレクトリに解凍しておき(.jar ファイルがいっぱい入っています。)、自身の java 実行環境に合わせてクラスパスを通せばよいです。
ここでは一応、筆者の環境(vscode, Extension Pack For Java)でのパスの通し方を紹介しておきます。
- 画面左下の ☕java Ready と表示された箇所をクリック

- Open Project Settings を選択

【図 2.3-2】 Open Project Settings - Libraries タブを開き、解凍した .jar ファイルを追加する。

【図 2.3-4】 Libraries タブを開き、解凍した .jar ファイルを追加する。 - Apply Settings をクリック

【図 2.3-4】 Apply Settings をクリック
導入出来たら、実装例をそのままコピペしてもらえばよいです。ZDD の本筋とは関係ないので解説は省略します。
参考にした記事 ↓(ライブラリの設計思想がなんとなくわかります)
あとは API とにらめっこしました。
2.4. テスト
実行結果:

おわりに+次回予告
お疲れ様でした。
今回は ZDD のベースとなる考え方として、再帰的な構築法を解説しました。
しかし、実際のところまだ ZDD の嬉しさについては全く解説していません。
ZDD のハイパー面白ポイントは部分集合族の“演算”が ZDD 上でも扱えるという点にあり、これにより様々な組合せ問題、すなわち条件を満たす組合せ集合全体からなる部分集合族を求める問題が簡単に解けてしまうのです。
そして、まさに今回目標としている Daily Akariも組合せ問題の一種で、ZDD の演算だけで解けちゃうわけです。凄い。
次回はそんな ZDD の演算を解説していきます。お楽しみに。
参考文献
-
S. Minato: "Zero-Suppressed BDDs and Their Applications", International Journal on Software Tools for Technology Transfer, Vol. 3, No. 2, pp. 156-170, Springer, May 2001.
*1:任意の完全二分木について、圧縮規則を繰り返し適用することで、対応した ZDD が手順に依らず一意に得られます。このことは、後ほど登場する 式(2), 式(3) をもとに帰納法を用いることで示せます。
*2:既約になっていない二分決定グラフも広く ZDD と呼ぶ場合もありますが、ここでは既約なものを指して ZDD と呼ぶことにします。
*3:筆者調べ。もっと大きい日もあるかもしれません。
*4:無論、 をプログラム上で表現する別の手段があれば、この手続きにより ZDD を構築できます。
*5:配列は、0番目から数え始めるのが一般的です。
*6:ここで紹介するハッシュ関数は筆者が実装時に作成した一例であり、人々がどのように実装しているのかは知りません。また、この関数がハッシュ関数として優れているかどうかの数学的な考察も一切していません。ごめんなさい。
Daily Akari を ZDD で解く話
はじめに
Daily Akari というパズルがあります。
ルールを見た瞬間、ZDD で解けるなぁと思ったので、解きました。
ZDD が何かについては、過去記事を参照してください。(全3部)
過去記事↓
ZDDと8-Queen problemの話【卒研お勉強枠①】 - 競プロ勉強メモ
ZDDによるN-Queen problemの解法を効率化する話(卒研お勉強枠②) - 競プロ勉強メモ
ZDDでマインスイーパーを解く話(卒研お勉強枠➂(最終回)) - 競プロ勉強メモ
Daily Akari のルール
- グリッド上に「空きマス」、「ブロック」、「数字付きブロック(以下、書かれた数字が
- 任意の空きマスには「灯り」を配置できる。灯りは上下左右方向のブロックに遮られていない空きマスを全て照らす。
- 以下の条件を満たすように灯りを配置出来ればクリア。
- 全ての空きマスを照らす。
- 全ての
- 灯りは自身以外に照らされてはならない。


ZDDで扱える形への帰着
-ブロックは卒研で扱ったマインスイーパーと全く同じなので処理できるとして、他の2ルールについても次のように「空きマスの部分集合に対する個数制限」の形で表現できます。(下記は、以下 条件A, B, C と呼びます。)
- 全ての空きマスについて、上下左右方向のブロックに遮られていない空きマスに灯りを少なくとも 1 つ配置する。
- 全てのブロック(グリッド左端の壁を含む)について、右方向にあるブロックに遮られていない空きマスに灯りを高々 1 つ配置する。
- 全てのブロック(グリッド上端の壁を含む)について、下方向にあるブロックに遮られていない空きマスに灯りを高々 1 つ配置する。
まあ実質マインスイーパーですね。(個人の感想)
空きマス全体を台集合として、べき集合を表す ZDD (0-枝と1-枝を順に繋げていくだけ)を構築しておきます。
あとは、ZDDでマインスイーパーを解く話(卒研お勉強枠➂(最終回)) - 競プロ勉強メモ で紹介した 演算や、それをヒント数字「以上」・「以下」に対応させた演算
、
を適用しまくれば解けます。やったね。
ソルバーの実装例
githubに置いときます。
ちなみに
ルール説明時に貼っていた問題は唯一解らしいです。
※ 頂点の数字を9で割ったときの商と余りがグリッドの座標に対応。青辺を通る時そのマスに灯りを配置する。

高速化について [追記:2025/04/12]
本解法は、盤面が大きくなるほど内部で構築される ZDD の節点数が指数的に増え、計算時間もメモリも爆増します。
しかし、ZDD の特徴として、演算の順序だったり組合せだったりを適切に決めることで同じ問題でもいい感じに節点数を抑えられることが知られています*1。そういったチューニングについては、思いつき次第追記していこうかなと思います。(データ集計とかは面倒なので、体感でよくなってそうなのを書きます。)
- 条件A について、「少なくとも 1 つ」ではなく「1 個以上 2 個以下」に制限し、
演算で処理する。[追記: 2025/04/12]
*1:卒研解説記事の第2部 でも触れています。
鳩ノ巣原理の良問を懐かしむ話【ABC227-D】
はじめに
鳩が 匹と鳩の巣が
個あり、各鳩はいずれか一つの巣に入っているとします。このとき、
ならば、必ず
匹以上の鳩が入った巣が存在します。あたりまえ体操ですね。この主張を、鳩ノ巣原理と呼びます。
この鳩ノ巣原理、競プロでたまーに出てきては猛威を振るっていくんですが、本記事では昔出てきてちょっと感心した良問を紹介します。
問題概要
扱う問題はこれ ↓ です
問題概要
個の部署があり、各部署
には
人の社員が所属している。
人組のプロジェクトを作る。ここで、
- 一つのプロジェクトに同じ部署に所属する社員が
人以上参加してはならない。
- 一人が
- 一つのプロジェクトに同じ部署に所属する社員が
- 最大でいくつのプロジェクトを作ることができるか。
- 実行時間制限: 2sec
(人の社員を持つこの社、ヤバすぎる)
やりがちな嘘解法
単純な解法として、貪欲法が浮かびます。
例えば として、(必要ならソートをして)部署が人数の昇順に並んでいるとして、
- 部署
~
から
- 部署
から
- 部署
から
- (以下繰り返し)
しかし、この解法は次のようなケースで最適解となりません。
(貪欲法だと 個しかプロジェクトが作れないですね。)
正しい解法
決め打ち二分探索
いつものです。
という判定問題を考え、
となる最大の
を二分探索します。
判定問題の解法
実は、任意の に対し次が成り立ちます:
\begin{equation} P(x) \Leftrightarrow \sum_{i=1}^{N} \min (A_i, x) \ge Kx \end{equation}
∵ 各部署について 人を超える分は無視してよいことに注意して(鳩ノ巣原理!)、各部署
の社員数を
とおきなおしたとき、
: 対偶を考えると、社員総数が足りていないので
は明らか。
: プロジェクトをそれぞれ
とする。部署順に社員全員を一列に並べて(同一部署の社員は自由な順で並べてok)前から順に
と番号をつけたとき、各社員
を
に参加させればよい*1。
提出コード
https://atcoder.jp/contests/abc227/submissions/64164861
おわりに
いかがでしたか?
鳩ノ巣原理には、しれっと出てきて「それはそう…」と落ち込ませる破壊力があります。つらい。
余談
鳩ノ巣原理を一般化したような立ち位置にある、Ramsey理論というものがあります。気になる人は組合せ論をやりましょう(布教)。
*1:この構成法は、問題概要の定義 2 つを両方とも満たしています。確認してみましょう。
【ABC388-G 解説?】並列二分探索に裏切られた話
はじめに
前回の記事 で並列二分探索というテクニックについて触れましたが、ABC388 にてついに並列二分探索の出番が来たので早速試してきました!
この記事でやること
-
G - Simultaneous Kagamimochi 2 の並列二分探索解法の解説
問題概要
問題概要
のサイズは
)
個の質問に答える。各質問
の内容は次の通り:
- 実行時間制限: 2sec
なお、各クエリは E問題 に相当します。
各クエリについての自然な発想として、以下のような貪欲法が浮かびます:
- 上の餅を昇順に見る。
- 1.の餅に対して、「まだ使っていない餅であって、下の餅として採用できる最小の餅」とマッチングさせる。
しかし、残念ながらこれは次のようなケースで壊れます。悲しい。
\begin{equation} A = [1, 2, 3, 4] \end{equation}
というわけで、各クエリだけでも解法をちゃんと考えなくてはなりません。
解法解説
クエリごとの解法について
作る鏡餅の個数を決め打ち二分探索すればよいです。
すなわち、 個の鏡餅を作れるか?という判定問題を考えると、小さい餅上位
個と大きい餅上位
個について、小さい順にマッチングさせられるか を見ればよいです。
つまり、各判定問題は で解けます。
※ 正当性の説明については E問題の公式解説 を参照してください
判定問題を並列に解く
前節での決め打ち二分探索を各クエリごとに行うと、全体 となり間に合いません。
前回の記事 でも解説した通り、並列二分探索は 個の判定問題を並列して解くことで高速化します。
各クエリ ごとに
個の鏡餅を作れるか?という判定問題を考え、並列に解く方法を考えます。
上側に置く餅を昇順に走査します。
このとき、前節での判定問題の解法によると、各クエリについて、マッチング相手として見るべき餅は1つだけです。
また、餅がサイズの昇順に並んでいることに注意すると、クエリを「今見ている上側の餅のindexからマッチング相手のindexまでの距離」*1で昇順にソートしてある時、マッチング相手としてよいかの判定結果に単調性が現れます。
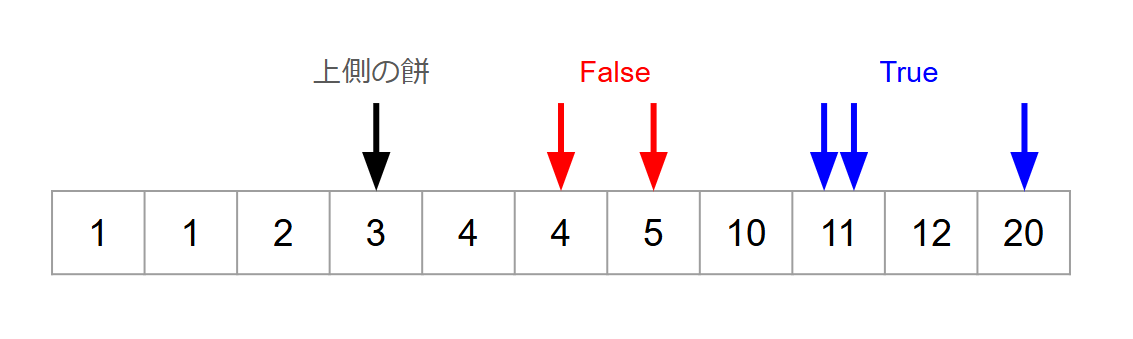
一度 False と判定されたクエリはその時点で 個の鏡餅が作れないことが確定するので、以降は考えなくてよいです。

以上を踏まえると、
- 上側の餅を走査しつつ、
- イベントソートによって判定するクエリを「今見ている上側の餅のindexからマッチング相手のindexまでの距離」の昇順に持ち、
- 「持っているクエリのうち先頭にあるもののマッチング相手が False になるならそのクエリの判定結果を False として捨てる」を while文 で処理
の要領で、 個の判定問題を並列して解くことができます。
クエリの持ち方としては、最小ヒープを使えばよいです。イベント終了の処理は 遅延評価 で行えばよいです。
計算量は です。
実装例
TLEしました笑。
おわりに
いかがでしたか?
TL が 2sec な時点で嫌な予感がしていたのですが、案の定でした。悲しい…
PyPyで通る気は今のところしていないのですが、高速な言語だと通ったりするんですかね。
最後までお読みいただきありがとうございました。
PyPyでもちゃんと通る解法(2024/1/15 追記)
各餅に対し「初めてサイズが2倍以上になる餅までの距離(存在しない場合は∞)」を並べた配列を二分探索や尺取法などで作成しておき、これを Range Max が で取れるデータ構造(Sparse Table 等)に載せておくことで、各クエリの決め打ち二分探索が
で解けるようです*2。何故気が付かなかったのか…。
典型を組み合わせて解くのが楽しかった話【ABC233-Ex 解説】
- はじめに
- 何が難しいのか
- 典型1: K番目の取得は決め打ち二分探索
- 典型2: マンハッタン距離は45°回転
- 典型3: 平面走査
- 典型4: 並列二分探索
- 典型5: Segment Tree
- おわりに
- 参考文献
はじめに
問題の解説をしつつ、競プロ楽しいよ~という布教をする回です。
特に、競プロを未経験の方に、競プロにおいて「典型*1を組み合わせて問題を解く」とはどのようなものなのかを実感してもらえたらと思います。
解説する問題はこいつ ↓ です。とりあえず読んでみてください。
※ 問題文中にあるマンハッタン距離とは、縦横でのみ移動できるとしたときの2点間の距離のことです。厳密には、2点 間のマンハッタン距離は
と表されます*2。
一見するとかなりシンプルな問題ですが、実は出題されているコンテスト(AtCoder Beginner Contest)の中ではかなりの難問に分類されており、典型知識を多重に組み合わせて解く必要があります。
どういった点が難しいのか、どのように解いていくのかを、競プロ関連の前提知識は使わないように(無理なところは適宜端折って)解説していくので、是非最後まで読んで「解けた!」が届く快感を味わってください。
また、できる限り丁寧に解説したつもりではありますが、問題自体が難しいので「解けた!」が万人には届けられないかもしれません。それでも、途中まで読んだ中で「なるほど!」が届けばなと思います。
何が難しいのか
改めて、問題の概要を確認します。
問題概要
- 二次元座標平面上に
- マンハッタン距離を用いるとして、座標
から
番目に近い点までの距離は?
- マンハッタン距離を用いるとして、座標
- 実行時間制限: 7sec
- 与えられる各座標の x, y はいずれも
以上
以下
この問題、答えを求めること自体はそう難しくはありません。
各質問 について、以下のような手順で質問に答えることができます:
とする配列
を作成する。
しかし、残念ながらこの解法で実装したコードを提出しても、TLE(Time Limit Exceeded / 実行時間制限超過)となり、不正解となります。プログラムの実行時間が長すぎるのでダメ!と怒られるわけですね。
この問題の実行時間制限は 7sec と設定されています。対して、プログラムの実行時間はどのくらいになるのでしょうか。
上記解法においてボトルネック(= 最も実行時間への影響が大きい箇所)となっているのは 2. のソート部分で、計算量は である(≒
の定数倍程度のステップ数を要する)ことが知られています*3。さらに、
回質問することを踏まえると、全体の計算量は
になります。
一般的なPCが1秒間に処理できるステップ数はおよそ 回程度と言われています。つまり、実行時間はざ~っくりと見積もると
\begin{align} \frac{10^5 \times 10^5 \times \text{log} 10^5}{10^9} \gt 50 \end{align}
という感じで、ガバガバ議論にはなりますが 7sec には到底収まりそうにないことが分かります。
更に言うと、上記解法の 1. だけ見ても計算量は で、この時点で既に 7sec は厳しいです。つまりは、「各質問ごとに各点を見る」という当たり前の処理すらさせてもらえない時間制限になっているのです。
シンプルな見た目をしていますが、実はかなりの無茶ぶりを要求されているということがご理解いただけたでしょうか?
いよいよここからは、競プロの典型知識を用いてこの問題を解きほぐしていきます!
典型1: K番目の取得は決め打ち二分探索
早速ですが、問題の言い換えを行います。
番目の質問
- 座標
は、次と同値です。
- 「
未満であるような点の個数は
ちょっと長いので、判定問題として
\begin{equation} P_i (d) :=(X_i, Y_i) からのマンハッタン距離が d 未満であるような点の個数は K_i 個未満であるか?\end{equation}
とおいてあげると、最終的に求めたいものは となる最大の
となります。
さて、ここからが重要です。
は、
についての単調性、すなわち
なる
について、
という性質を持ちます。( を大きく取れば距離
未満の範囲にある点の個数は単調増加するので、当然です。)
この性質を用いれば、次のスライドのように範囲を半分ずつ絞っていくことで、判定問題 を高々
回程度解くだけで所望の
を求めることができます。いわゆる二分探索というやつです。
なお、 と評価できるので、
を解く回数は高々
回程度です。
このように、何かしらの数値を求める問題に対して単調性のある判定問題に置き換えて二分探索を適用する手法を、決め打ち二分探索と呼びます。
とはいえ、まだ問題はほとんど解決していません。
というのも、決め打った に対して判定問題
が高速に解けないようでは、判定問題に置き換えた意味がないからです。
ここからは、この判定問題を解く方法を掘り下げていきます。
典型2: マンハッタン距離は45°回転
からマンハッタン距離が
未満である領域を図示すると、次のような菱形になります。
は、この領域に含まれる点が
個未満かどうかを判定する問題に相当します。

ただ、この菱形というのは色々と扱いづらいです。
そこで、以下のような座標変換を行ってみます:
\begin{align} u &:= x+y \\ v &:= x-y \end{align}
各位置ベクトルに対して45°の回転行列をかけたあと 倍すると理解してもよいでしょう。この変換により先ほどの領域は、u-v座標系で表すと次の通り正方形になります。

これにより、正方形区画に点が何個含まれるかを求める問題に帰着することができました。これが解けるかどうかは別として、少なくとも菱形で考えるよりはなんとなく見通しがよさそうですよね。
このように、マンハッタン距離に関する問題はとりあえず45°回転してから考えるというのが典型となっています。
以降はこのu-v座標系で議論を進めていきます。
なお、座標変換により
となっています。
典型3: 平面走査
「正方形区画内の点の個数」を、もう少しだけ扱いやすい形で表現します。
座標平面上の各格子点を二次元グリッドのマス目に置き換え、点が存在するなら 1, しないなら 0 を書き込みます。これにより、二次元グリッド上で正方形区画内の総和を求める問題として定式化できます。
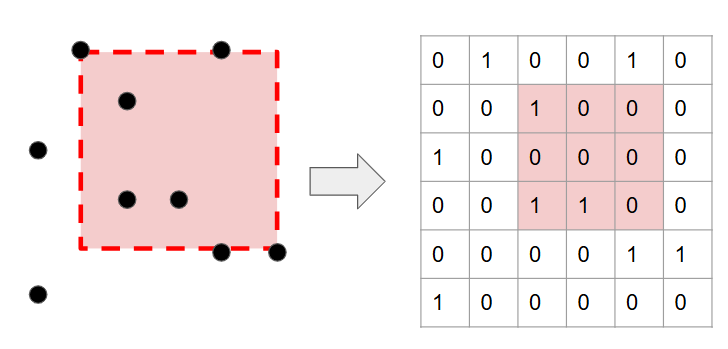
なお、 の範囲を思い出すと、グリッドサイズが縦横いずれも
となっていることに注意しましょう。(つまり、プログラム上で明にこのグリッドを二次元配列で持つことはできません*4。悲しい。)
さて、このような大きなグリッドに関する問題に対しては、平面走査と呼ばれる典型的なアプローチがあります。まずは、次のスライドをご覧ください。
何がしたいのかは一旦置いておくとして、行ごとに走査しながら配列に値を加算していく様子が伺えます。このように、何かしらのデータを持ち、行(あるいは列)ごとにデータを更新しながら平面を走査することを、総称して平面走査と呼びます。
急にわけのわからない操作をし始めたぞコイツ…?と思われているかもしれませんが、実はこの操作に超重要な秘密が隠されています!
↓この緑部分の総和(4)から…

↓この黄色部分の総和(1)を引くと…

求めたかった正方形区画の総和(4-1 = 3)が得られます!
この理由は単純で、矩形和の引き算に対応しているからです。
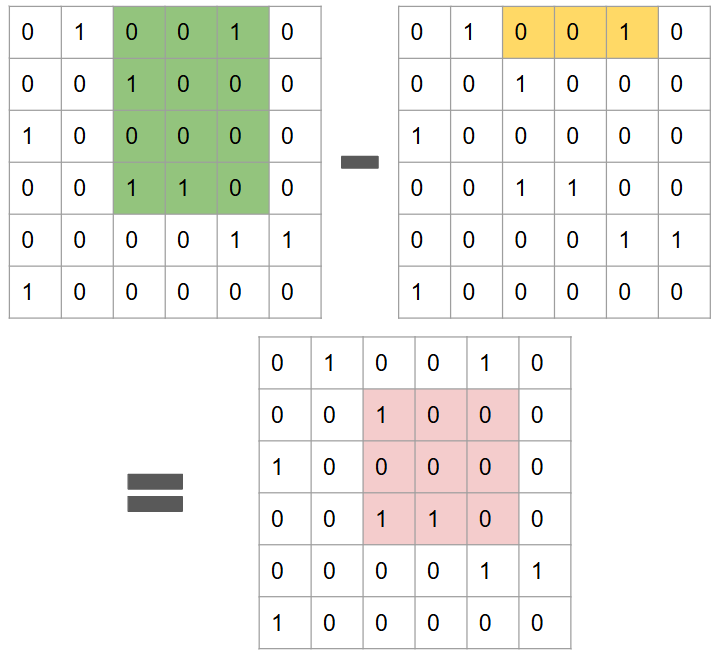
ということで、正方形区画の総和は次の要領で求められます:
- 平面走査を行う。その途中で、次の二つの値を別途保存しておく。
- 黄色部分の総和
- 緑部分の総和
- 上記で保存した2数の差が答え。
計算量を考えてみましょう。グリッドの横幅を ,
を
とおくと、
- 平面走査については、長さ
の配列を用意したうえで更新が
- 黄色部分、緑部分の総和を求めるのは
で、これは平面走査の
- 黄色部分、緑部分の総和を求めるのは
- → 判定問題
1回あたり
- → 全体
あれ…??????全然よくなってない…(´・ω・`)
典型4: 並列二分探索
平面走査などというトンデモびっくりアプローチまで取り出して頑張ったのに、計算量は何も改善されていませんでした。果たして、今までの努力は何だったのでしょうか…。
ここで、全く新しい視点を導入します。
今までは質問1つごとにどう解くか?ということだけを考えていましたが、思い切って 個の質問を一斉に解くことを考えてみましょう。
より正確には、 個の質問に対して二分探索を同時に実施し、
個の判定問題
を1回の平面走査中にまとめて解くことにします。
今までの議論と同様に考えると、グリッド上に 個の正方形区画が与えられ、それぞれの総和を求める問題を解くことになります。実はこれ、正方形が何個だろうとやることは全く変りません。すなわち、平面走査の途中で各正方形区画ごとに対応した黄色部分の総和と緑部分の総和を保存し、最後にそれぞれ差をとればよいです。
ありがとう、平面走査…!!!!
計算量を考えます。
- 平面走査については、長さ
- 黄色部分、緑部分の総和を求めるのは各
で、まとめると
- 黄色部分、緑部分の総和を求めるのは各
- → 判定問題
をまとめて解く処理1回あたり
- → 全体
惜しい!!
ここにきて、配列の区間和を計算する箇所がボトルネックになってしまいました。
典型5: Segment Tree
いよいよ最後の典型です。
平面走査中に行いたい処理を改めて書き下すと、次の2つです:
- 1点更新
- 区間和取得
平面走査のデータを通常の配列で持ってしまうと、どうしても区間和取得に区間長分の計算量がかかってしまいます。
そこで登場するのが、競プロにおいて典型中の典型、キング・オブ・典型データ構造である Segment Tree です*5。
Segment Tree でデータを持つと、上記の2操作がいずれも (
: グリッドの横幅)で処理できます。
詳細は端折りますが、ざっくり概要だけ解説します。
Segment Tree は図のような完全二分木の構造をしており、葉の部分には平面走査のデータ、その他の節点には左右の子の和が保存されています。ここで、完全二分木の高さは 、節点数は
になることに注意してください。

このようにデータを持つと、1点更新は図のように 個の節点の更新で済みます。

また、任意の区間和についても参照する節点数が で抑えられることが示せます*6。

というわけで、Segment Tree を用いれば1点更新と区間和の取得の両方を高速に処理できます。
Segment Tree を用いた場合の計算量は、次の通りです:
- 平面走査については、長さ
- 黄色部分、緑部分の総和を求めるのは各
で、まとめると
- 黄色部分、緑部分の総和を求めるのは各
- → 判定問題
- → 全体
長い長い戦いの末、ついに2乗の項を完全に消すことができました。
ステップ数の計算はもう面倒なのでしませんが、実行時間はちゃんとこの解法で制限に収まります。
以上、解説を終わります。お疲れさまでした。
おわりに
典型に典型を重ねて考察を進める雰囲気を、少しは味わっていただけたでしょうか?
個人的には、自身の知りうる典型知識を如何にうまく組み合わせて解法に到達するかを考えるのが、競プロ(というか、AtCoder Beginner Contest)の醍醐味のように思います。
この記事を読んで、内容を全部理解できたかどうかは正直どうでもいいです。(そもそも初学者が解く問題の難易度じゃないので。)
それよりも、なんとなく「面白そう!」と思った方は、間違いなく競プロ向いてると思うので、是非この機会に始めてみてはいかがでしょうか。
逆に、「難しそう…こわ…近寄らんとこ…」と感じた方であっても、「はじめに」で述べた通りこの記事の中に少しでも「なるほど!」と高揚感を得られた箇所があれば、それが競プロを楽しむモチベーションになっているということだけでもを知っていただければ幸いです。
それでは。
参考文献
Editorial - AtCoder Beginner Contest 233
CODE THANKS FESTIVAL 2017 H - Union Sets (並列二分探索解法) - ARMERIA
【Trie木】ABC377G - Edit to Match の図説
この記事でやること
ABC377G-Edit to Match の図説です。やってることは公式解説と同じです。
解法
便宜上 を空文字列として、
まで処理済みで
を
したTrie木を考えます。(Trie木を知らない方は、参考文献に記載した記事などを参照してください。)
ここで、 に対する解は
になります。上図の場合、
から
または
が最短で、答えは
になります。
これは、各ノード について
を記録しておくことで高速に解くことができます。
Trie木の根から のノードまでのパスを
としたとき、求める解は
となります。
また、 は
の帰りがけにchminすることで簡単に更新できますね。
計算量は、各文字列 に対し
*1 になります。
提出コード
Python (PyPy 3.10-v7.3.12)
Submission #59196277 - TOYOTA SYSTEMS Programming Contest 2024(AtCoder Beginner Contest 377)
おわりに
公式解説、こういう挿絵とかあったらもっとわかりやすいのにね…。
参考文献
トライ木(Trie木) の解説と実装【接頭辞(prefix) を利用したデータ構造】 | アルゴリズムロジック
*1:Trie木の枝をhashmapで持った場合の期待計算量。配列で持つなら文字種数σ倍が付きます。
Aho-Corasick法をしっかりと理解する話
はじめに
個のキーワード
が定められている環境下で、入力テキスト
からそれらの出現位置を全列挙するクエリを考えます。
文字列の一致判定はローリングハッシュなどを用いて定数時間でできるにしても、含まれている場所が分からない以上は、テキスト1つあたり 程度の計算量になってしまいそうです。
Aho-Corasick法は、キーワードに対して で工夫したTrie木を作る*1ことで、クエリあたり
で処理できます。強い。*2
本記事は、Aho-Corasick法の考え方やざっくりとしたアルゴリズム、計算量評価の方法をまとめたものです。これを読めば、Aho-Corasick法をしっかりと理解でき、自力で実装できるようになる…かも?
この記事でやること
Aho-Corasick法をできる限り丁寧に解説します。
また、最後にPython(PyPy)での実装例を載せてあるので、ご自由にお使いください。
Aho-Corasick法の解説
Trie木を効率よく辿る
まずキーワードでTrie木を作っておきます。

このTrie木において、 の
文字目(以後、
と表記、0-indexedとする。)を左端とするキーワードを見つけたい場合、
- Trie木の根に"駒"を置き、
とする。
- 駒のいるノードに文字
の枝が存在する限り、その先のノードに駒を進めて
をインクリメントすることを繰り返す。
とすればよいです。
具体例として、 として考えてみましょう。


しかし、これを各左端について行うと になるので、まだまだ嬉しくありません。
Aho-Corasick法では、この左端の切り替えを効率よく行います。
試しに、【図2-2】の続きを考えてみましょう。
今、 の枝が駒のいるノードに存在しないため、駒を進めるループを脱出した状態です。なので、次は駒を根に戻し
として再度駒を進めるループに入ります。
このループは と駒を進めますが、この
と進める部分は、前回のループで
と進めたことを思い出すと無駄な動きをしているような気がします。どうせなら根に戻らず直接
のノードに移したいですね。
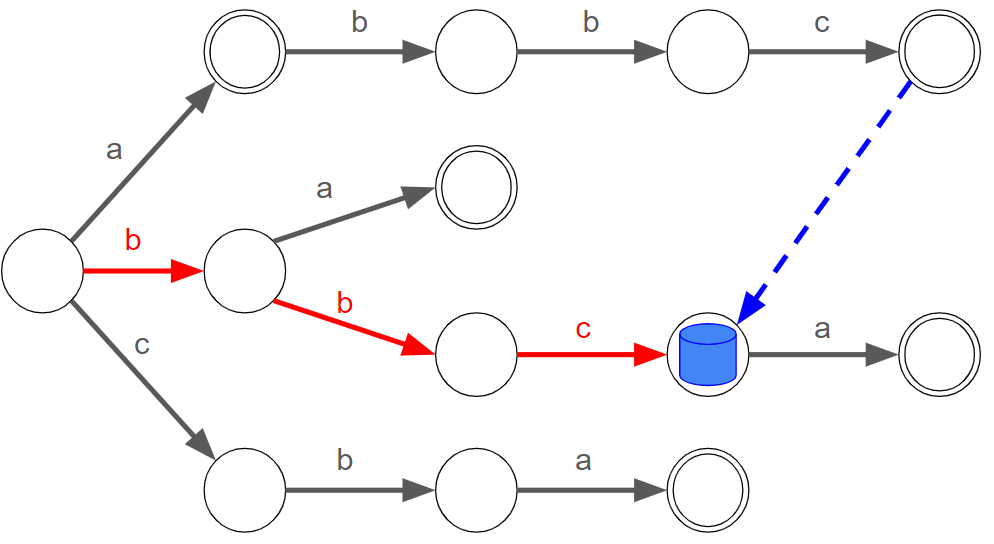
これを一般的に述べます。
便宜上、根から駒がいるノードまでのパスにより得られるテキストを読み込んでいるテキストと呼ぶことにします。
ループが止まった後の駒の移動先は、「読み込んでいるテキストの接尾辞(自身は除く)であって、キーワードの接頭辞として含まれる最長のもの」を表すノードとすればよいです。(なので、 で止まったあと駒は
に移動します。)
Trie木の構造上、根以外のどのノードに駒があったとしても対応した上記の移動先のノードが一意に定まります。そこで、各ノード について対応する移動先のノードを
と表すことにしましょう。根以外の全てのノードに対して
が既に求まっているものと仮定すると、ざっくり次のような手順で全てのキーワードを列挙できます:
- 駒をTrie木の根に置き、
に対して、順に以下を行う:
- 駒がいるノードが根でなく、かつ文字
の枝が存在しない限り、駒を
に移すことを繰り返す。
- 駒がいるノードに
- 読み込んでいるテキストの接尾辞として含まれるキーワードを列挙する。(※)
- 駒がいるノードが根でなく、かつ文字
この手順で全てのキーワードが過不足なく列挙できていることは、(※)の操作によって を末尾とするキーワードが全て列挙されていることから分かります。
列挙の方法としては、 を根に到達するまで辿り、キーワードそのものになっているものを抽出すればよいです。さらに、
を適切に経路圧縮して得られる「読み込んでいるテキストの接尾辞(自身は除く)として含まれる、最長のキーワード」を表すノードへの辺を用意しておけば、計算量を出現回数で抑えられます。*3
ここで、次のスライドショーを見てもらうとわかる通り、読み込んでいるテキストは駒の移動に合わせて常に右方向に動きます。つまり、尺取法の要領で駒の移動回数が高々 回に抑えられるわけですね。
ということで、あとは各ノードに対する を前計算するパートを倒せばよいです。
fail の前計算
の定義を思い出すと、
の移動先のノードはTrie木において自身より浅い位置にあります。そこで、
について深さ
以下の全てのノードの
が求まっていると仮定して、深さ
のノード
について
を求め方を考えます。また、便宜上
としておきます。
の親を
とします。また、根から
までのパスによるテキストを
、
から文字
の枝を通って
に到達するものとします。
が指すノードは、「
の接尾辞(自身は除く)であって、キーワードの接頭辞として含まれる最長のもの」を表すノードでした。これは必ず
の接尾辞に
をつけた形をしている点に注意すると、次の手順で
を求めることができます:
とする。
が根でない かつ
が
の枝を持たない限り、
とすることを繰り返す。
とする。そうでないなら、
とする*4。
そして、根から始めるBFSにて を見るときに、各子ノード
に対して、上記の処理をしたのちにキューに入れていくことで、全てのノードの
を求めることができます。
計算量を考えてみましょう。BFS部分は でいいとして、
を求めるループが問題です。実は、各キーワード
について、
の各文字のノードによるループの合計回数が高々
回で抑えられます(※※)。よって、前計算全体で
となります。
(※※)の証明
キーワード について、「
の接尾辞(自身は除く)であって、キーワードの接頭辞として含まれる最長のもの」の長さを
とし、
の末尾
文字による文字列を
とします。次に、
から末尾の
を削った部分文字列対して同様の操作を行い
と
を得ます。以下これを繰り返して
、
が得られたところで
となったとします。また、
、
とします。
このとき、各 について、
の各文字のノードの
を求めるループは高々
回で抑えられます。なぜなら、
のノードについては、親ノードの
であることに注意すると、高々
回のループで求まる。
のノードについては、親ノードの
の枝が存在するため、ループは1回しか発生しない。
となるからです。
競プロへの応用
冒頭で示したような列挙クエリは、計算量的に競プロではおそらく問われません。
そこで、列挙の代わりに各キーワードの出現回数を数え上げる問題を考えてみましょう。
単純なのは、各キーワードがそれぞれ何回出現したかを表す配列を用意して、前述の(※)を利用してインクリメントしていくという方法です。しかし、これでは計算量が変わらず出現回数に依存してしまいます。
解決法としては、各ノードについて(※)が始まるノードになった回数をカウントしておき、最後に木dpの要領で、回数を に沿って配りつつキーワードの末尾ノードに到達するごとにその値を配列に加算していけばよいです。
問題例 ↓
Pythonでの実装例
- PyPy3.10-v7.3.12 にて動作確認済。
使用例↓
Submission #56078430 - Toyota Programming Contest 2024#7(AtCoder Beginner Contest 362)
ちなみに
これは驚愕の事実なのですが、Aho-Corasickは 「えいほこらしっく」であって、「あほこらしっく」ではないそうです。
参考文献
- Alfred V. Aho and Margaret J. Corasick. 1975. Efficient string matching: an aid to bibliographic search. Commun. ACM 18, 6 (June 1975), 333–340.
*1:正確に述べると、これは内部のTrie木でハッシュテーブルを用いた場合の期待計算量になっています。配列でTrie木を作る場合は文字種数σ倍かかるかわりに最悪計算量になります。どちらで実装するかはお好みでどうぞ。
*2:なお のようなケースを考えれば出現回数を壊せるので、競プロ目線では出現回数に依存しないクエリを考えることが多そうです。
*3:経路圧縮のために余分に潜る操作は、高々Trie木のノード数回しか発生しないため、Trie木構築時の計算量に押しつけて"ならす"ことができます。
*4:この場合での は必ず根になります。そこで、根について本来存在しない文字の枝を全て自身へのループとしておけば、ここの場合分けをなくすこともできます。